Edward William Lane's Arabic-English Lexicon - a digital version
12th August 2015
Windows test version available
If anyone is interested in testing the software under Windows, please drop me an email at1st June 2015
OSX test version available
If anyone is interested in testing the software under OSX, please drop me an email at28th April 2015
A DMG file
After much head-scratching, I've finally managed to build a DMG that works on a refresh install of OSX Mountain Lion.Some tidying needs to be done but the end is in sight.
I wonder if a dmg built on 64bit OSX Mountain Lion will run other versions of OSX.
28th March 2015
Beta testers
Within the next few weeks I hope to have a version ready for testing, so I'm looking for people to try the software and let me know of any problems, missing features etc. (This version will not include documentation.)
I plan to do OSX first and then Windows, so as a first step I aim to build a DMG on OSX Mavericks and make that available. Given how little I know about OSX this should be fun.
Eventually I will release binaries via public github repository, but in the meantime I need some way of getting the dmg out for testing. Dropbox maybe?
If you would like to give the software a try out and report back any problems, please email me (Graeme Andrews) at Please specify your operating system version in the email. I'll send you an email when the software is ready.
You should bear in mind that this is something I do in my spare time, so it is hard for me to give reliable timescales.
9th February 2015
Themes
I've been organizing the various way of customizing the application into 'themes'.A theme is made up of:
- The fonts and colours used by the application, set by a stylesheet.
- The icons that are used.
- The shortcuts and keystrokes that control the application.
- The appearance of the lexicon entries. Again fonts, colours set through a stylesheet.
- The structure and layout of those entries determined by an XSLT script
- Default settings for many, many things. For example, printer settings, default zoom, and whether to restore visible entries from when the application last closed.
Everything that makes up a theme exists in a subdirectory so creating a new theme is simply a matter of copying the entire directory and playing around with it, safe in the knowledge you are not going to break anything.
Other news
Not much progress on the documentation and I'm doing pretty well at putting it off. I know good documenation is important; if only that made it interesting.
There's a saying in IT to the effect that you don't have a backup system until you've done a recovery. Well, it turns out I had about 75% of a backup. Not too bad really :-(.
10th January 2015
Documentation
Apart from minor code changes, I've started working on the documentation and will post some of it here. The following section, taken out of context, is part of a description of how to customize the application at the most detailed/technical level.
Perseus digitization
To show what the process of digitization involves, in the image below we have on the left the text from Vol 2, page 817 of the Lexicon, showing the root خنص and on the right the corresponding lines from one of the files supplied by the Perseus project.

The text has been encoded in XML, a popular means of storing plain text. All that's relevant here is:
- XML has 'tags' that appear like <this> and are ended like </this>
- tags can have attributes, which are name/value pairs
- tags can be be embedded within other tags
For example,
This begins with a tag named "div2" and one if its attributes is named "type" and its value is "root". The tag names are not arbitrary - they are part of the Text Encoding Initiative tagset. To quote:
The mission of the Text Encoding Initiative is to develop and maintain a set of high-quality guidelines for the encoding of humanities texts, and to support their use by a wide community of projects, institutions, and individuals.
The set of tags that make up the TEI standard is large; fortunately only on small subset is used in the encoding of Lane's Lexicon.
For the "div2" tag, the value of the "type" attribute tells us that this a root, the value of the "n" attribute, "xnS", tells us what the root is. (Within the XML all of the Arabic text is written according to the Buckwalter transliteration.)
A few lines below the "div2" tag and embedded within it, there is the first of three "entryFree" tags, each one encoding a headword. Each "entryFree" tag has all the text that makes up its entry in the lexicon.
While the headwords (entryFree) are embedded within the root (div2), the roots themselves are embedded within a "div1" tag that looks like this:
In effect there is a heirarchy: div1 (letter) / div2 (root) / entryFree (headword).
When the application is built, the XML files are parsed and all the
relevant information is stored in a database. Within the application the structural information re-appears in the tree structure of the contents panel with letters
at the top level and headwords at the bottom.
For each headword, the XML fragment consisting of the <entryFree> tag and its children are stored in the database and it this that makes it possible to customize the page.
How a page is built
To show a root and its headwords, the relevant records from the database are read and the XML for each headword is processed and converted to HTML. The actual appearance of the text i.e. its font, color, size etc is controlled through a stylesheet just as in any web page.
In the image below the same text is show on the left as it appears in the application, on the right is the HTML that is the source of that text:
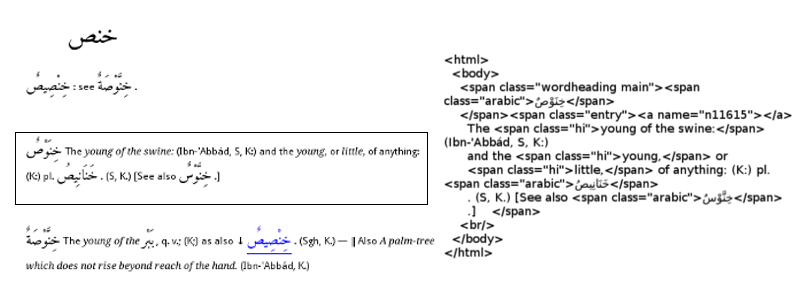
It is the "class" entries in the HTML that control the appearance of the text. For example, the Arabic text has a class "arabic". The relevant entry from the stylesheet is:
.arabic { font-family : Amiri;font-size : 18px}
So, to change the Arabic font used on all the pages it is simple a matter of changing 'Amiri' to the name of another font. In the same way the English text is controlled through the class "entry":
.entry { margin-left : 30px; font-family : Droid Sans;font-size : 12px; }
The application provides a convenience method of changing these two entries via the Tools menu so it is not always necessary to edit the stylesheet. However that method only changes the font name and size, for more fine grained control it is necessary to edit the stylesheet. It should be noted that not all HTML is supported - for more details see here. (The linked page refers to 'text widgets' - each headword in the application is such a widget.
31st December 2014
Fixing a broken link
To make a link point to the right place, find the correct entry in the contents panel (i.e. the letter/root/headword tree on the left) and then drag it from the tree and drop it on the link.


This can be done more than once, so mistakes can be fixed. I will probably provide an import/export facility so fixed links can be shared.
25th December 2014
Tidying the XML
The quality of the transcription from the original text to XML is impressive and I can only guess at the amount of work involved. Nevertheless, some errors have crept through - sometimes they're minor typos that have no further effect, but sometimes a mistake in one character can have very a visible outcome. In the screenshot below, the entries for the root نضخ have been added to those for root نضح:

Here's how a root appears in the XML:
<div2 n="nDH" type="root" org="uniform" sample="complete" part="N" TEIform="div2">When the root entry for نضخ was added, it was mistakenly added as nDH (which is the Buckwalter transliteration of نضح) instead of nDx. That's alpl it took.
My copy of the XML files are kept under version control: the commit logs tell me that so far I have made 262 changes. I expect there will be more to come.
17th December 2014
Resolving cross references
To quote from Lane's Preface:
In order to facilitate the reference, an arrow-head (↓) is inserted to render conspicuous a word explained in a paragraph headed by another word.) Several obvious advantages result from this arrangement; not the least of which is a considerable saving of room.The text contains 36031 cross-references. In the application, Lane's arrow-head becomes a clickable link.
At the moment, 25541 of those cross-references are resolved, leaving 10490 broken links.
I'm working on a two-pronged approach: reduce that number to something more respectable and provide a simple method for the user to fix a broken link.
Here's what a broken link looks like:

- The text has been marked up in such a way that the link extends over more than one word.
This is is a the cross-reference is marked up in Perseus:
<orth type="arrow" lang="ar">A_iy~aAka waAlt~aA^a*~iY</orth>
It would be relatively simple to convert all these multi-word links to single word links during the database build, something the user would never see. (The Perseus text uses the Buckwalter transliteration of Arabic.) - When the link text is followed immediately by more Arabic, the down arrow is shown out of place.
If you have any comments about the above, please contact me at: